Setup
I created new free MongoDB cluster on Atlas and loaded sample data into this cluster.

As you can see cluster:
- has version 5.0.13
- is deployed on GCP / Belgium
- contains 3 nodes in Replica Set
So, what is this “replica set”?
Replica set
According to documentation:
A replica set in MongoDB is a group of mongod processes that maintain the same data set.
Thanks to that we can get redundancy and high availability.
Always one of the nodes in replica set is selected as primary and others are called secondary or sometimes arbiter. But we will not focus on what type is responsible for.
The most important things to remember are:
- All writes goes through primary and are replicated to secondaries
- Reads can be executed both on primary and on secondaries
- When current primary will stop responding, new one will be selected
If you want to learn more, I recommend that you check the documentation.
Read preference
As I mention above, reads can be executed from primary or secondary.
Read preference is option which lets us specify where reads operations should be sent
Modes
Available modes for readPreference are:
primary- reads only from primary nodeprimaryPreferred- mostly from primary, if unavailable then from secondariessecondary- reads only from secondary nodessecondaryPreferred- mostly from secondaries, if unavailable then from primarynearest- reads from selected replica set member based on latency (details)
Default mode
When you connect to yours MongoDB cluster by default primary read preference is used.
I’ve created simple script to generate traffic on my cluster:
1
2
3
4
5
6
7
8
9
db = connect('${mongodb_uri}');
function delay(time) {
return new Promise(resolve => setTimeout(resolve, time));
}
for (let i = 0; i < 1_000; i++) {
delay(500).then(() => db.posts.findOne({}));
}
After running it, metrics look like: 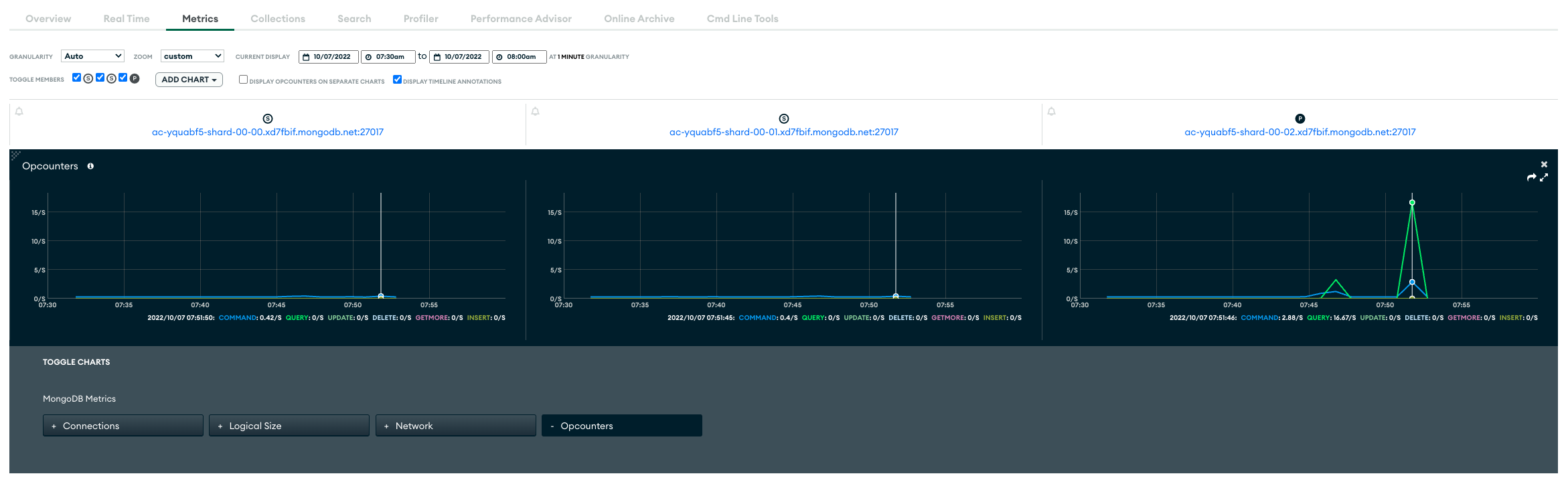
So, all reads were made from primary node (it is marked by letter P above chart).
Reads from secondary
When I simply modify script (only but adding ?readPreference=secondary at the end of the mongo_uri) and run it again, I can see difference on the charts:
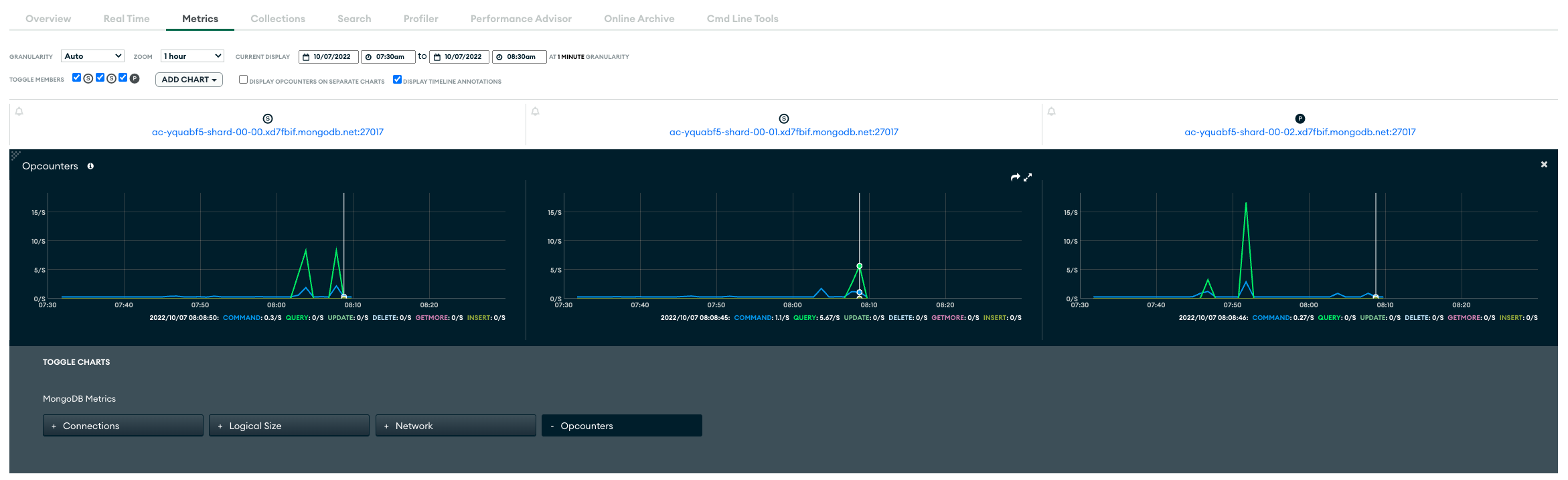
Read operations were made from secondary nodes, so now the whole read traffic to database is split to two secondaries. Now primary will be responsible only for write operations. It should have significant impact on resource consumption and database performance.
Warnings
This may not be the best choice for everyone. Replication from primary to secondaries may take some time or even fails. It will depend on the replica set configuration. Few use cases for various modes are described in MongoDB documentation.
If you have MongoDB in version below 4.0, reading from secondaries may lead to slower responses from database. It’s because that in previous versions reading from secondaries was blocking. In 4.0 version Non-blocking secondary reads have been introduced (more details here).
Comments powered by Disqus.